笔记本分为studio与work,work为空,studio中包含:爬虫学、Feedbot、Misskey.py
Misskey.py :misskey.py 是misskey api的python格式化工具,可以便捷地使用api执行命令,因为file上传的字段名与firefish有所不同,想要拉下来修改包装成firefish.py ,但测试失败,没有掌握pip库打包调试的方法。可以弃置。Feedbot:是一些机器人脚本的小实现,一些片段可以保留
爬虫学:包含学习爬虫的笔记,参考的是Zotero-文库-编程-《Python网络爬虫权威指南(第2版)》
世间的知识臃杂繁多,若要选出一条原则来将其分个三六九等,我以为"经世致用"一词最为恰当,认识的最终目的就是实践嘛。大多数人学的大多数东西都在学习阶段过后丢失,把学习当作一种纯粹的认识活动,在非常可惜,明明可以有更多的用途的,不将其运用到实实在在的东西上论其为暴敛天物也不为过。实践有困难的,有简单的,有所见即所得,有所见非所得的,劳动的本质就是物质的搬运加工,爬虫作为一种劳动,是值得研究一番的,下面将以爬虫为例,来进行学习应用。
beautiful soup 可以很便捷地抓取页面信息。
python中的解析器有如下几种:
常见的html.parser
lxml:单独安装,可以容忍机构杂乱的htmlhtml5lib:具备更加强大的容错性,速度更慢。
对于各种情况进行处理,以防无输出不知所措。
HTTPError:网页在服务器不存在
UrlError:服务器不存在
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from urllib.request import urlopen from urllib.error import HTTPErrorfrom urllib.error import URLErrorfrom bs4 import BeautifulSoup try : html = urlopen('https://blog.si-on.top/about/' ) except HTTPError as e : print ("报错啦:" ,e) except URLError as e : print ("服务器找不着了!" ) else : bs = BeautifulSoup(html.read(), 'html.parser' ) testtag = bs.h1 print (testtag)
1 2 3 4 5 6 7 8 9 10 11 12 from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen('https://sunsetbot.top/map/' ) bs = BeautifulSoup(html.read(), 'html.parser' ) img_tag = bs.find('img' , {'id' : 'map_img_src' }) if img_tag: img_src = img_tag.get('src' ) firemap = "https://sunsetbot.top" + img_src else : print ("未找到指定的图片标签" )
任何 HTML(或 XML) 文件的任意节点信息都可以被提取出来,只要目标信息的旁边或附近有标签就行。
bs4抓取信息的过程就是一个筛选的过程。现代网页大多都有很丰富的css(层叠样式表),可以从css的class与id里来筛选出大多数标签。
find_all(tag, attributes, recursive, text, limit, keywords)
tag: 抓取对应标签名,单个标签直接写'标签名',如find_all('div').对于多个标签,可以写成列表的形式:find_all(['div1','div2','div3'])
attributes:抓取该标签下的若干属性和对应的属性值。如抓取子虚栈的“玩物”页面的设备标签:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen('https://blog.si-on.top/AwesomeHub/equipment/' ) bs = BeautifulSoup(html.read(), 'html.parser' ) list = bs.findAll('div' ,["equipment" ]) print (list )print ("测试2" )black_list = bs.find_all('div' ,["icat-equipment-name" ],string=lambda text: text and '黑' in text) for self in black_list: print (self .get_text())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from urllib.request import urlopen, urlretrievefrom urllib.parse import quotefrom bs4 import BeautifulSoup import rehtml = urlopen('https://sunsetbot.top/map/' ) bs = BeautifulSoup(html.read(), 'html.parser' ) img_tag = bs.find('img' , {'id' : 'map_img_src' }) img_re_src = img_tag.get('src' ) encoded_path = quote(img_re_src, safe='/%' ) firemap = "https://sunsetbot.top" + encoded_path urlretrieve(firemap, '0828.jpg' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from misskey import Misskeyfrom urllib.request import urlopen, urlretrievefrom urllib.parse import quotefrom bs4 import BeautifulSoup import remk = Misskey("https://si-on.top" , i="******" ) html = urlopen('https://sunsetbot.top/map/' ) bs = BeautifulSoup(html.read(), 'html.parser' ) img_tag = bs.find('img' , {'id' : 'map_img_src' }) img_re_src = img_tag.get('src' ) encoded_path = quote(img_re_src, safe='/%' ) firemap = "http://sunsetbot.top" + encoded_path print (firemap)with open ('902.jpg' , "rb" ) as f: data = mk.drive_files_create(f)
时间线的小逆流,抵抗大众的洪流
赤翳♨️(火烧云预测):抓取信息 ,每天预报日出、日落的火烧云情况。
♨️赤翳一隅 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 from misskey import Misskeyfrom urllib.request import urlopen, urlretrievefrom urllib.parse import quoteimport urllib.requestfrom urllib.error import HTTPError, URLErrorimport osfrom bs4 import BeautifulSoupimport requestsfrom datetime import datetimeimport rebotkey = "****" sunsettime = datetime.now().strftime("%Y年%m月%d日" ) mk = Misskey("https://实例地址" , i= botkey ) html = urlopen('https://sunsetbot.top/map/' ) bs = BeautifulSoup(html.read(), 'html.parser' ) img_tag = bs.find('img' , {'id' : 'map_img_src' }) img_re_src = img_tag.get('src' ) print (img_re_src)encoded_path = quote(img_re_src, safe='/%' ) firemap = "http://sunsetbot.top" + encoded_path print (firemap)def download_image (url, save_path='firecloud.jpg' ): try : headers = {'User-Agent' : 'Mozilla/5.0' } req = urllib.request.Request(url, headers=headers) print (f"尝试下载: {url} " ) urllib.request.urlretrieve(url, save_path, lambda blocknum, blocksize, totalsize: print (f"下载进度: {blocknum * blocksize} /{totalsize if totalsize > 0 else '未知' } " , end='\r' )) print (f"\n文件已保存到: {save_path} " ) return True except HTTPError as e: print (f"HTTP错误 {e.code} : {e.reason} " ) print (f"请检查URL是否正确: {url} " ) return False except URLError as e: print (f"URL错误: {e.reason} " ) return False except Exception as e: print (f"其他错误: {str (e)} " ) return False download_image(firemap) with open ('firecloud.jpg' , "rb" ) as f: data = mk.drive_files_create(f) fc = data['id' ] print (fc)fc = data['id' ] note = mk.notes_create( text=f"""🌇{sunsettime} 火烧云预报来啦!#预报 #一隅""" .strip(), file_ids = [fc], ) print (note)
雾笼🌫️(雾气预测):抓取信息 ,每晚预报第二天的雾气情况。
🌫️雾笼一隅 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 from misskey import Misskeyfrom urllib.request import urlopen, urlretrievefrom urllib.parse import quoteimport urllib.requestfrom urllib.error import HTTPError, URLErrorimport osfrom bs4 import BeautifulSoupimport requestsfrom datetime import datetimeimport rebotkey = "******" fogtime = datetime.now().strftime("%Y年%m月%d日" ) mk = Misskey("https://实例地址" , i= botkey ) html = urlopen('https://www.nmc.cn/publish/fog.html' ) bs = BeautifulSoup(html.read(), 'html.parser' ) img_tag = bs.find('img' , {'id' : 'imgpath' }) img_re_src = img_tag.get('src' ) img_raw = re.sub(r'/medium' , '' , img_re_src) print (img_raw)def download_image (url, save_path='fog.jpg' ): try : headers = {'User-Agent' : 'Mozilla/5.0' } req = urllib.request.Request(url, headers=headers) print (f"尝试下载: {url} " ) urllib.request.urlretrieve(url, save_path, lambda blocknum, blocksize, totalsize: print (f"下载进度: {blocknum * blocksize} /{totalsize if totalsize > 0 else '未知' } " , end='\r' )) print (f"\n文件已保存到: {save_path} " ) return True except HTTPError as e: print (f"HTTP错误 {e.code} : {e.reason} " ) print (f"请检查URL是否正确: {url} " ) return False except URLError as e: print (f"URL错误: {e.reason} " ) return False except Exception as e: print (f"其他错误: {str (e)} " ) return False download_image(img_raw) with open ('fog.jpg' , "rb" ) as f: data = mk.drive_files_create(f) fc = data['id' ] print (fc)fc = data['id' ] note = mk.notes_create( text=f"""🌫️{fogtime} 雾预报来啦!#预报 #一隅 #foggy #雾天""" .strip(), file_ids = [fc], ) print (note)
XKCD中文站:抓取中文站 的漫画,每五点监控更新发布。
XKCD抓取 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 from misskey import Misskey from urllib.request import urlopen, urlretrieve from urllib.parse import quote from bs4 import BeautifulSoup import requests from datetime import datetime import re import os botkey = "******" mk = Misskey("https://实例地址" , i= botkey ) html = urlopen('https://xkcd.in/' ) bs = BeautifulSoup(html.read(), 'html.parser' ) least_pic = bs.find('div' , {'id' : 'strip_list' }) if least_pic: first_link = least_pic.find('a' ) if first_link: text = first_link.get_text() match = re.search(r'\[(\d+)\]' , text) if match : latest_id = match .group(1 ) print (f"最新文章ID: {latest_id} " ) pic_file = f"{latest_id} .png" if not os.path.exists(pic_file): pic_main = bs.find('div' , {'class' : 'comic-body' }) pic_link = 'https://xkcd.in/' + pic_main.find('img' )['src' ] pic_title = pic_main.find('img' )['title' ] pic_detail = bs.find('div' , {'class' : 'comic-details' }).get_text() urlretrieve(pic_link, pic_file) print (f"图片已下载: {pic_file} " ) with open (pic_file, "rb" ) as f: data = mk.drive_files_create(f,name=pic_title) fc = data['id' ] print (fc) fc = data['id' ] note = mk.notes_create( text=f"""**{pic_title} **\n 『*{pic_detail} *』 \n #xkcd #漫画 #汉化 #一隅""" .strip(), file_ids = [fc], ) print (note) else : print (f"图片已存在,跳过下载: {pic_file} " )
~~双日一言(美文阅读):抓取more2read 信息,每周一、三、五、日发送,格式化文本。~~轻松调频于2025.12.23已经停播
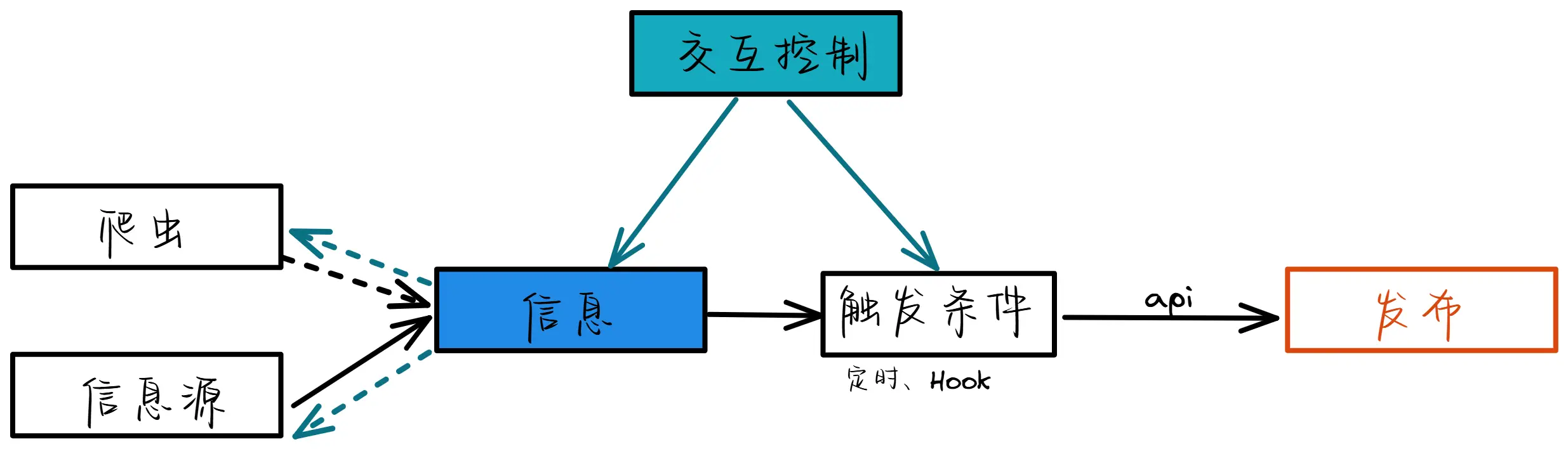
第一类机器人独立版:有源机器人,发送利用维护好的数据库中的信息。重复周期最起码一个季度,且同一季度内的任意两条信息不得在两个季度的范围内重复。古文机器人:维护一个古文数据库,每日发送一篇古文。
第二类机器人:图灵机器人(可交互)。
RSS机器人:A(用户)指定命令“/订阅”+“链接”后,机器人把链接添加到订阅列表,并返回输出,包括订阅结果、此机器人rss链接、订阅的两条展示。而后机器人在这条嘟的下面回复若干条投票(仅仅用户A可见),来让用户指定该条订阅的更新频率,展示样式(如标签、频道等),自定义效果(内置变量)等,每次投票确定后机器人用缓存的rss来输出展示效果,最后确定样式后机器人删除嘟文下所有结果。
自动微积分机器人:维护好积分题目
偏好型机器人,抓取本地博文信息,对于符合兴趣的加以回应(设定性格、偏好),转载,或者评论。利用联网自洽的数据进行模拟信息发布。发布频率、时间限制,尽可能模拟真人。的数据库,每日发送。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 from misskey import Misskeyfrom urllib.request import urlopen, urlretrievefrom urllib.parse import quotefrom bs4 import BeautifulSoup import requestsfrom datetime import datetimeimport rebotkey = "Hjknkjndfjksldfjsdfls" sunsettime = datetime.now().strftime("%Y年%m月%d日" ) class FirefishAPI : def __init__ (self, base_url, api_key=None , bearer_token=None ): self .base_url = base_url.rstrip('/' ) self .api_key = api_key self .bearer_token = bearer_token def _headers (self ): headers = {'Content-Type' : 'application/json' } if self .bearer_token: headers['Authorization' ] = f'Bearer {self.bearer_token} ' return headers def _body (self, data ): if self .api_key: data = dict (data or {}) data['i' ] = self .api_key return data def call (self, path, method='POST' , data=None , files=None ): url = f"{self.base_url} {path} " headers = self ._headers() if files: response = requests.post(url, headers=headers, files=files, data=self ._body(data)) else : response = requests.request(method, url, headers=headers, json=self ._body(data)) response.raise_for_status() try : return response.json() except Exception: return response.text def notes_create (self, data ): return self .call('/notes/create' , data=data) mk = Misskey("https://si-on.top" , i= botkey ) html = urlopen('https://sunsetbot.top/map/' ) bs = BeautifulSoup(html.read(), 'html.parser' ) img_tag = bs.find('img' , {'id' : 'map_img_src' }) img_re_src = img_tag.get('src' ) encoded_path = quote(img_re_src, safe='/%' ) firemap = "http://sunsetbot.top" + encoded_path print (firemap)urlretrieve(firemap, '904.jpg' ) with open ('904.jpg' , "rb" ) as f: data = mk.drive_files_create(f) fc = data['id' ] print (fc)fc = data['id' ] if __name__ == "__main__" : api = FirefishAPI( base_url="https://si-on.top/api" , api_key= botkey , ) note = api.notes_create({ "text" : f"""{sunsettime} 火烧云""" .strip(), "lang" : "zh-hans" , "fileIds" : [fc], }) print (note)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 from urllib.request import urlopen, urlretrievefrom urllib.parse import quoteimport requestsimport reimport jsonimport timeimport schedulefrom datetime import datetimeimport osbotkey = "Hjknkjndfjksldfjsdfls" class FirefishAPI : def __init__ (self, base_url, api_key=None , bearer_token=None ): self .base_url = base_url.rstrip('/' ) self .api_key = api_key self .bearer_token = bearer_token def _headers (self ): headers = {'Content-Type' : 'application/json' } if self .bearer_token: headers['Authorization' ] = f'Bearer {self.bearer_token} ' return headers def _body (self, data ): if self .api_key: data = dict (data or {}) data['i' ] = self .api_key return data def call (self, path, method='POST' , data=None , files=None ): url = f"{self.base_url} {path} " headers = self ._headers() if files: response = requests.post(url, headers=headers, files=files, data=self ._body(data)) else : response = requests.request(method, url, headers=headers, json=self ._body(data)) response.raise_for_status() try : return response.json() except Exception: return response.text def notes_create (self, data ): return self .call('/notes/create' , data=data) def load_book_data (): """从aaa.json文件加载书籍数据""" try : with open ('aaa.json' , 'r' , encoding='utf-8' ) as f: return json.load(f) except FileNotFoundError: print ("错误: 未找到aaa.json文件" ) return None except json.JSONDecodeError: print ("错误: aaa.json文件格式不正确" ) return None def get_next_article_index (): try : with open ('article_index.txt' , 'r' ) as f: return int (f.read().strip()) except FileNotFoundError: return 0 def save_article_index (index ): with open ('article_index.txt' , 'w' ) as f: f.write(str (index)) def format_content (content_list ): full_content = '' .join(content_list) first_char = full_content[0 ] formatted_content = f"$[x2 {first_char} ]{full_content[1 :]} " return formatted_content def send_daily_article (): book_data = load_book_data() if not book_data: print ("无法加载书籍数据,请检查aaa.json文件" ) return api = FirefishAPI( base_url="https://si-on.top/api" , api_key=botkey, ) current_index = get_next_article_index() if current_index >= len (book_data["articles" ]): current_index = 0 article = book_data["articles" ][current_index] formatted_content = format_content(article["content" ]) note_text = f""" <center>**$[font.serif $[fg.color=67B7F7 {article['title' ]} ]]**</center> <center> $[font.serif {book_data['name' ]} ]</center> $[font.serif {formatted_content} ] #古文 #{book_data['name' ]} """ try : note = api.notes_create({ "text" : note_text, "lang" : "zh-hans" , }) print (f"{datetime.now().strftime('%Y-%m-%d %H:%M:%S' )} 已发送: {article['title' ]} " ) next_index = (current_index + 1 ) % len (book_data["articles" ]) save_article_index(next_index) except Exception as e: print (f"发送失败: {e} " )
github有一个仓库包含了许多古文典籍的json,但是没有段落分割,都是一句一句的,还有有规律出现的空格,似乎是从epub中提取而出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 from urllib.request import urlopen, urlretrievefrom urllib.parse import quoteimport requestsimport reimport jsonimport timeimport schedulefrom datetime import datetimebotkey = "asfnjksdfbfbsdfsjkd52454fsd54f5sd4f5s" book_data = { "name" : "庄子" , "description" : "《庄子》又名《南华经》,是战国中期庄子及其后学所著道家经文。到了汉代以后,尊庄子为南华真人,因此《庄子》亦称《南华经》。其书与《老子》《周易》合称" 三玄"。《庄子》书分内、外、杂篇,原有五十二篇,乃由战国中晚期逐步流传、揉杂、附益,至西汉大致成形,然而当时流传版本,今已失传。目前所传三十三篇,已经郭象整理,篇目章节与汉代亦有不同。内篇大体可代表战国时期庄子思想核心,而外、杂篇发展则纵横百余年,参杂黄老、庄子后学形成复杂的体系。" , "articles" : [ { "title" : "内篇·逍遥游" , "content" : [ "北冥有鱼,其名为鲲。鲲之大,不知其几千里也。化而为鸟,其名为鹏。鹏之背,不知其几千里也。怒而飞,其翼若垂天之云。是鸟也,海运则将徙于南冥。南冥者,天池也。" , "《齐谐》者,志怪者也。《谐》之言曰:" 鹏之徙于南冥也,水击三千里,抟扶摇而上者九万里,去以六月息者也。"野马也,尘埃也,生物之以息相吹也。天之苍苍,其正色邪?其远而无所至极邪?其视下也,亦若是则已矣。" ] }, { "title" : "内篇·齐物论" , "content" : [ "南郭子綦隐机而坐,仰天而嘘,荅焉似丧其耦。颜成子游立侍乎前,曰:" 何居乎?形固可使如槁木,而心固可使如死灰乎?今之隐机者,非昔之隐机者也。"" , "子綦曰:" 偃,不亦善乎,而问之也!今者吾丧我,汝知之乎?女闻人籁而未闻地籁,女闻地籁而不闻天籁夫!"" ] } ] } class FirefishAPI : def __init__ (self, base_url, api_key=None , bearer_token=None ): self .base_url = base_url.rstrip('/' ) self .api_key = api_key self .bearer_token = bearer_token def _headers (self ): headers = {'Content-Type' : 'application/json' } if self .bearer_token: headers['Authorization' ] = f'Bearer {self.bearer_token} ' return headers def _body (self, data ): if self .api_key: data = dict (data or {}) data['i' ] = self .api_key return data def call (self, path, method='POST' , data=None , files=None ): url = f"{self.base_url} {path} " headers = self ._headers() if files: response = requests.post(url, headers=headers, files=files, data=self ._body(data)) else : response = requests.request(method, url, headers=headers, json=self ._body(data)) response.raise_for_status() try : return response.json() except Exception: return response.text def notes_create (self, data ): return self .call('/notes/create' , data=data) def get_next_article_index (): try : with open ('article_index.txt' , 'r' ) as f: return int (f.read().strip()) except FileNotFoundError: return 0 def save_article_index (index ): with open ('article_index.txt' , 'w' ) as f: f.write(str (index)) def format_content (content_list ): full_content = '' .join(content_list) first_char = full_content[0 ] formatted_content = f"$[x2 {first_char} ]{full_content[1 :]} " return formatted_content def send_daily_article (): api = FirefishAPI( base_url="https://si-on.top/api" , api_key=botkey, ) current_index = get_next_article_index() article = book_data["articles" ][current_index] formatted_content = format_content(article["content" ]) note_text = f""" <center>**$[font.serif $[fg.color=67B7F7 {article['title' ]} ]]**</center> <center> $[font.serif {book_data['name' ]} ]</center> $[font.serif {formatted_content} ] #古文 #{book_data['name' ]} """ note = api.notes_create({ "text" : note_text, "lang" : "zh-hans" , }) print (f"{datetime.now().strftime('%Y-%m-%d %H:%M:%S' )} 已发送: {article['title' ]} " ) next_index = (current_index + 1 ) % len (book_data["articles" ]) save_article_index(next_index) def job (): if datetime.now().hour == 6 : send_daily_article() if __name__ == "__main__" : print ("庄子嘟文机器人已启动..." ) print (f"将在每天早上6点发送文章,共{len (book_data['articles' ])} 篇文章" ) schedule.every().hour.do(job) while True : schedule.run_pending() time.sleep(60 )