我最讨厌的事情有两个:一是学习,二也是学习。
——Sion
我不善于拒绝,所以讨厌被灌输思想,恐惧那种潜移默化,润物无声的影响。
听播客是一件非常危险的事。
赫胥黎在《美丽新世界》中描绘的在睡觉时默默播放音频的教化方式一度让我非常震惊——潜意识中接收的信息很大程度上不会经过判断就直接进入脑海,不经过滤,全盘接收乃至全盘接受!“杨子见逵路而哭之,为其可以南可以北;墨子见练丝而泣之,为其可以黄可以黑。”思想不深入,没有对某些事情深入地批判性地思考,形成自己的见解,那么就很容易被其他人的观点带着走,用心理学非官方术语来说,就是被“洗脑”。
可能有人会说“一派胡言!又不是超人,有没有时间,我怎么可能对所有事情都形成自己的看法?与其保持蒙昧无知,被人“洗脑”也何尝不是一件美事?”我承认,今人的灵魂是由亿万万个古人的灵魂所组成,人的本质就是复读机。没有人可以对任何事情,甚至是几件事情提出自己独到的新鲜的见解。
然而这并不代表你就因之而放弃主观能动性,放弃否定的权力,放弃重塑思想的自由意志。
否定,是一种权力,更是一种能力。
“否定之否定”,是马原中提到过的关于事物发展的一般规律。核心观点就是事物发展要经过三个过程:
肯定阶段:形成对某个事物的认识
否定阶段:对既有的认识进行否定
否定之否定阶段:对认识否定本身进行否定
这种规律可以从近代以来国人对儒学的态度看出来:以前不断继承,后来大力批判,到现在“批判地继承”。任何学科的尽头都是哲学,否定之否定是哲学上的一个基本规律,它可以适用于任何事物,对观点的形成也是如此。
简言之,在我看来防止被洗脑/形成自己观点 的方法就是去主动否定,解构之后再去建构。从子虚栈23年来的数据分析报告来看,80%的人只是接受,15%的人进行了否定,只有不到5%的人做到了否定之否定。任何阶段都不能停留太久,尤其是第二阶段,呆的久了人就会崩溃,正如友人@一身都是月 曾说过“批评的目的不是解构而是建构 ”。就算是最后一阶段也是认识发展中的一个子过程,只有不断的“肯定-否定-否定之否定-肯定-否定-否定之否…”
所以听播客是一件非常危险的事,你不仅要听它,还要否定它,是不是顿时觉得很累了?
Easy~,认识发展就是这样,意识到平常经验里的问题,即使没有刻意去行动,也会在未来产生动因与积极影响。
我常听的播客不多,长听的播客更少,而CNR的播客节目《美文阅读more to read》是仅有的伴随我最久的一个节目。从白雪皑皑到绿意盎然,从2020到2024,19到23,从大一到毕业,从学校到工厂车间,沈汀老师的声音一直伴随着我。
回味着那些声音,我能感受到曾经聆听时阳光的压力;
Ahhhh,怎么写着写着,文风这般文艺伤感做作了,回来吧!
简单介绍下这个播客节目:
节目分为三个部分
🕡每天早上六点半播放,总时长半个小时
每周一三五播送,二四六重播,周日会把这周播送的内容做一个精选总结(剪辑而成)
可以在官网轻松调频 与CGTN (有节目文稿),以及各大播客平台Spotify、Itunes等进行收听
节目内容包括三部分,都按照英文-中文-中文解读-英文复述 进行
DailyQuote:一句名人的话
Poems of the Day:一首诗歌
Beauty of Words:一篇文章,文章过长时会分两次播送
节目精彩,有很多有意思的文字非常值得保存下来,在2022年暑假,当时一时兴起在学LaTeX \LaTeX L A T E X
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 {\tiny }\documentclass [UTF8,11pt,,oneside,final, ]{ctexart} \usepackage {graphicx,parallel,fontawesome5,multicol,xcolor,media9}\usepackage [top=2.54cm, bottom=2.54cm, left=2.07cm, right=2.07cm,headsep=1.0cm,marginparwidth={3cm}]{geometry}\usepackage [margin=10pt,font=small,labelfont=bf,]{caption}\usepackage {hyperref}\hypersetup {colorlinks=true, linkcolor=black,filecolor=black,urlcolor=black, citecolor=black,pdftitle=美文阅读,pdfauthor=Sion tine,pdfsubject={英语,紫晶计划},pdfkeywords={诗歌,文章},pdfstartview=FitB}\usepackage {ctex}\ctexset { section/name = {第,天}, section/format =\huge \bfseries \raggedright , subsection/name = {}, subsection/format =\centering , secnumdepth ={0}, } \newcommand {\dailyquote }[3] { \ctexset { subsection/format =\raggedright , } \begin {figure}[h] \centering \includegraphics [width=0.7\linewidth ]{#3 } \label {fig:#3 } \end {figure} \subsection {{\color {violet}\faQuoteLeft }\quad \large \bfseries DailyQuote} \begin {quotation} #1 \begin {flushright} \textit {——#2 } \end {flushright} \end {quotation} \ctexset { subsection/format =\centering , } } \newcommand {\poem }[4]{ \subsection {{\color {violet}\faFeather }\quad \large \bfseries #1 } \begin {flushright} \textit {#2 } \end {flushright} \begin {Parallel}{84mm}{82mm} \ParallelLText {#3 } \ParallelRText {#4 } \end {Parallel} } \newcommand {\poems }[6]{ \subsection {{\color {violet}\faFeather }\quad \large \bfseries #1 } \begin {flushright} \textit {#2 } \end {flushright} \begin {Parallel}{#3 }{#5 } \ParallelLText {#4 } \ParallelRText {#6 } \end {Parallel} } \newcommand {\music }[4]{ \subsection {{\color {violet}\faMusic }\quad \bfseries #1 } \begin {flushright} \textit {#2 } \end {flushright} \begin {Parallel}{86mm}{82mm} \ParallelLText {#3 } \ParallelRText {#4 } \end {Parallel} } \newcommand {\words }[3]{ \subsection {{\color {violet}\faBookReader }\quad \large \bfseries #1 } \begin {flushright}\textit {#2 }\end {flushright}{ #3 } } \begin {document} \pagestyle {empty}\begin {titlepage}\begin {center} {\zihao {0} \textbf {{\color {violet}\faPodcast } 美文阅读\footnote { {\color {violet}\faQuoteLeft }:DailyQuote\qquad {\color {violet}\faFeather }: Poem of the Day \qquad {\color {violet}\faBookReader }:Beauty of Words }}}\\ \vspace {4ex} {\zihao {3}\textbf {\faDoorOpen :2022年7月16日}}\\ \vspace {4ex} {\zihao {3}\textbf {\faDoorClosed :2022年9月23日}} \begin {figure} \centering \includegraphics [width=1\linewidth ]{more2read.jpg} \caption *{} \label {fig:more2read} \end {figure} \end {center}\end {titlepage}\thispagestyle {empty}\pagestyle {empty}\newpage \tableofcontents \include {7-16.tex}\include {7-18.tex}\include {7-20.tex}\include {7-22.tex}\include {7-25.tex}\include {7-27}\include {7-29}\include {8-01}\include {8-03}\include {8-05}\include {8-07}\include {8-08}\include {8-10}\include {Before}\end {document}
后来维护太麻烦,每次都要手动复制粘贴,坚持了没几天就放弃了。
在2023年某一天,eafm的客户端不能用了,节目文稿显示不出来,在用户的追问下,沈老师在节目后边加了一句“请大家前往CGTN获取节目文稿”。
我当时听到后去官网查了查 ,确实有,从第一期到最新一期都有,但是一篇一篇复制显然不切实际,又联想到RSSHub项目,便试探性地提了个issue,没想到一个月后,一位名为5upernova-heng 的大佬帮忙实现了功能,再次感谢你!
然而虽然读起来方便了,每次更新节目,手机的RSS阅读器上都能出现文稿,但是没有pdf化让我仍觉得虚无缥缈,pdf才是正道!才是信息不朽的正确方式。
之后一段时间,我又利用notion里的RSS插件来自动抓取Notion - 美文阅读 但是文稿不能分类,只是每天抓取一对文字放表格里,也没什么意思,又放弃了。
昨天夜班醒来后,思维很活跃。
联想到最近学的python应该可以实现将RSS解析成个字典,网上搜了搜,果然有一个名为 feedparser 的2002年就发布的python包可以实现。
实操了下,太简单了!格式化地非常好,一下子提起了我对编程的兴趣。
就如同当年学LaTeX \LaTeX L A T E X
1 2 3 4 5 6 7 8 9 10 11 import feedparsermore2read_rss_url = 'https://rsshub.rssforever.com/cgtn/podcast/ezfm/4' more2read_raw = feedparser.parse(more2read_rss_url) print ("RSS源版本:" , more2read_raw.version) print ("抓取到的RSS数量:" , len (more2read_raw.entries))print ('标题:' , entry.title) print ('发布日期:' , entry.published) print ('格式化的发布日期:' , entry.published_parsed) print ('封面图' , entry.image) print ('音频时长:' , entry.itunes_duration)
抓取到的正文(储存在entry.summary)是html格式的,很不友好,便找来一个html2text对它进行格式化:
1 2 3 main_text_html = entry.summary main_text = html2text.html2text(main_text_html)
这是最关键的一步,将text文稿分割成三部分,因为文稿中"Daily Quote"、“Poem of the Day”、"Beauty of Words"是固定的,不需要特别复杂的算法,通过简单的find函数就可以进行分割,分割后再把本身去除,放到字典里:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 main_sort = { "Daily Quote" : "" , "Poem of the Day" : "" , "Beauty of Words" : "" } start_positions = { "Daily Quote" : main_text.find("Daily Quote" ), "Poem of the Day" : main_text.find("Poem of the Day" ), "Beauty of Words" : main_text.find("Beauty of Words" ) } for section, start_pos in start_positions.items(): if start_pos != -1 : start_pos += len (section) + 1 next_section = min ([pos for pos in start_positions.values() if pos > start_pos], default=len (main_text)) main_sort[section] = main_text[start_pos:next_section].strip()
生成了字典还只是第一步,最重要的是能自己导出成tex格式的文档。因为rss源还贴心地提供了封面链接,我们就可以顺便把封面下下来,再整理下日期格式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def struct_time_to_formatted_date (time_struct ): date_format = "%Y_%m_%d" return strftime(date_format, time_struct) def tex_struct_time_to_formatted_date (time_struct ): date_format = "%m月%d日" return strftime(date_format, time_struct) date = struct_time_to_formatted_date(entry.published_parsed) date_tex = tex_struct_time_to_formatted_date(entry.published_parsed) cover_url = entry.image.href cover_filename = f"{date} .jpg" cover_directory = join('source' , 'cover' ) cover_path = join(cover_directory, cover_filename) if not exists(cover_directory): makedirs(cover_directory) with requests.get(cover_url, stream=True ) as r: if r.status_code == 200 : with open (cover_path, 'wb' ) as f: for chunk in r: f.write(chunk) else : print (f"Failed to download cover image: {cover_url} " )
最后按照tex写好的函数格式,将字典写入到tex中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 relative_cover_path = join('cover' , cover_filename) tex_content = "" tex_content += "\\section{" + date_tex + "}\n\n" tex_content += "\\dailyquote{" + main_sort["Daily Quote" ] + "}{" + relative_cover_path + "}\n\n" tex_content += "\\poems{" + main_sort["Poem of the Day" ] + "}\n\n" tex_content += "% \\words{" + main_sort["Beauty of Words" ] + "}\n" tex_filename = f"{date} .tex" file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'source' , tex_filename) with open (file_path, 'w' , encoding='utf-8' ) as file: file.write(tex_content)
生成好封面与tex文档后,我们只需要在注tex里引用下,就可以生成了
没有对中英文进行分割,排版效果不好
文稿有时没有不提供译文,需要手动搜原文,或者用机器翻译进行处理
工具如果纯粹成了工具,那它也就死了。
这个自动化流程如果能全程自动化,实现上述的两个不足,且一点不需要人的介入,自动抓取,自动生成,自动发布,那么从代码的角度来讲,它是完美的,但从创造性的角度来说,它已经死透了。
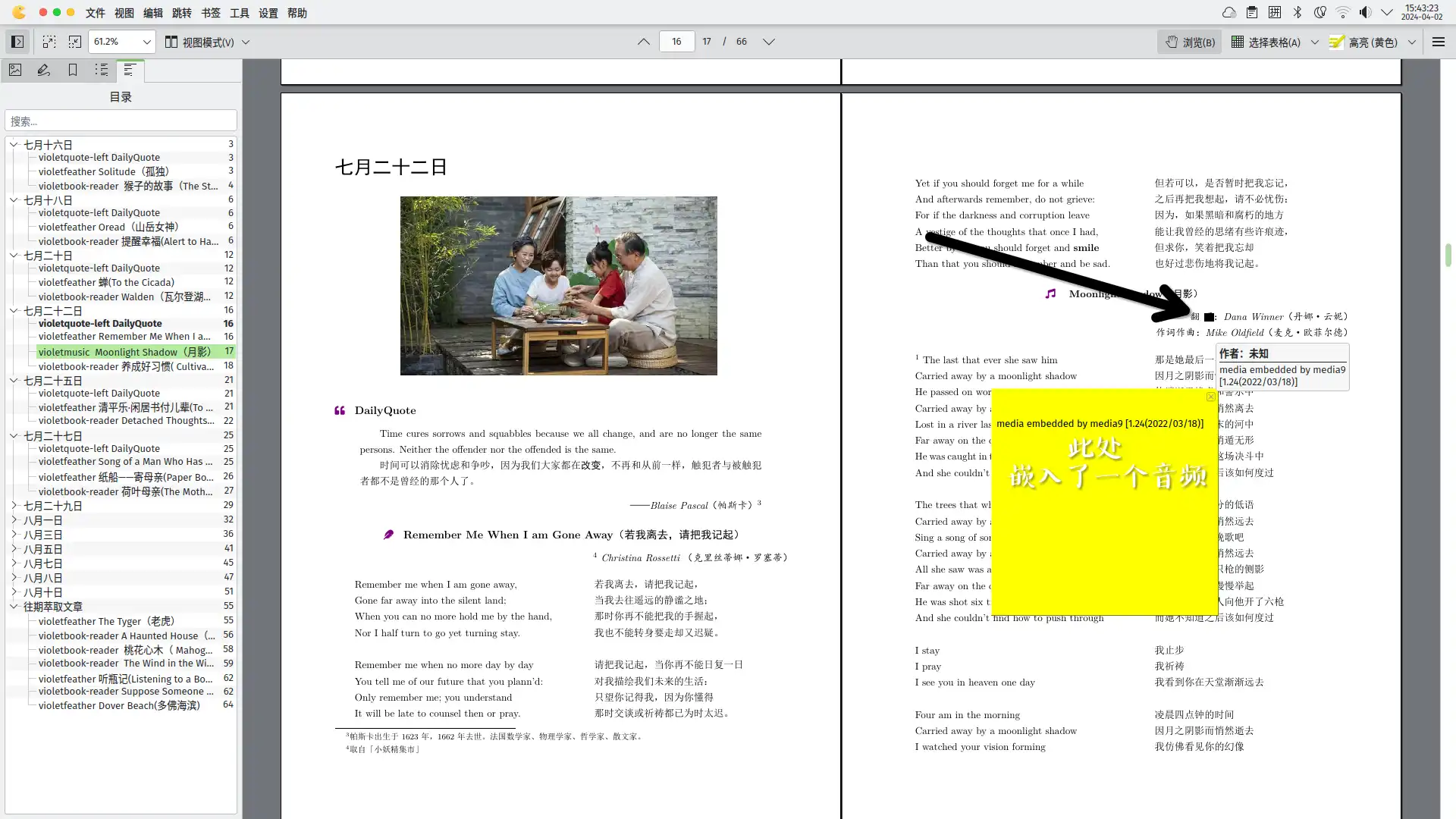
留心的人会注意到,在上文中《pdf化初次尝试》我放了张图片,介绍的是一个嵌入音频的pdf页面,这就是突破沈汀老师阴影的一个尝试,他在选择文字、文章、诗歌来表达自己的看法,我同样也可以选择添加音乐、歌词、摄影到文档中来表达自己的看法。
有了人,工具才不会沦为工具。
所以下一步规划是:在自动抓取文章的基础上,并添加一些具有“子虚栈特色”的内容进去,让项目保持活力。
最后:
Long live the Podcast!
Long live the Project!
Long live the Free Will!
2025.5.27 重启,将日志与之结合。